

今回はPythonの機械学習(人工知能の一種)を使って、テキスト・文書を自動で分類するWebアプリを作ってみました。
1. Webアプリの概要
今回作ったのは、テキストや文書をカテゴリに自動で分類する簡易アプリです。本アプリの機能は、入力したテキストや文書を、3つのカテゴリ「人工知能」「投資」「細胞」に自動で分類します。
2. 機械学習のアルゴリズム
テキストや文書を分類するのに機械学習のアルゴリズムを使用しました。ベイジアンフィルタ(ナイーブベイズ)と呼ばれる確率統計的な手法です。
この手法では、単にプログラムに特定の単語(キーワード)を教えるのではなく、事前に大量のテキストや文書をランダムに学習させます。実際に学習に使用したデータを下記に示します。

上記のデータは「テキスト」と「カテゴリ」をペアにしたもので、それぞれのカテゴリごとに15個、計45個用意しました。テキストはWikipediaで各カテゴリを検索して集めました。
学習させたこのデータをもとに、未知のテキストや文書のカテゴリを自動で分類してくれるようになります。学習させたデータは少ないですが、単語(名詞に限定)の出現回数という特徴量で精度よく分類することができます。
3. Webアプリのデモ
では、Webアプリを使ってみます。入力欄に「人工知能」「投資」「細胞」の何れかに関連するテキストや文書を記入します。
3.1.「ディープラーニング」を判定
先ずは、Wikipediaで「ディープラーニング」を検索した文書を入力してみます。実際に、この文書が「人工知能」のカテゴリに分類されることを期待します。
文書を入力した後に「判定」ボタンをクリックします。
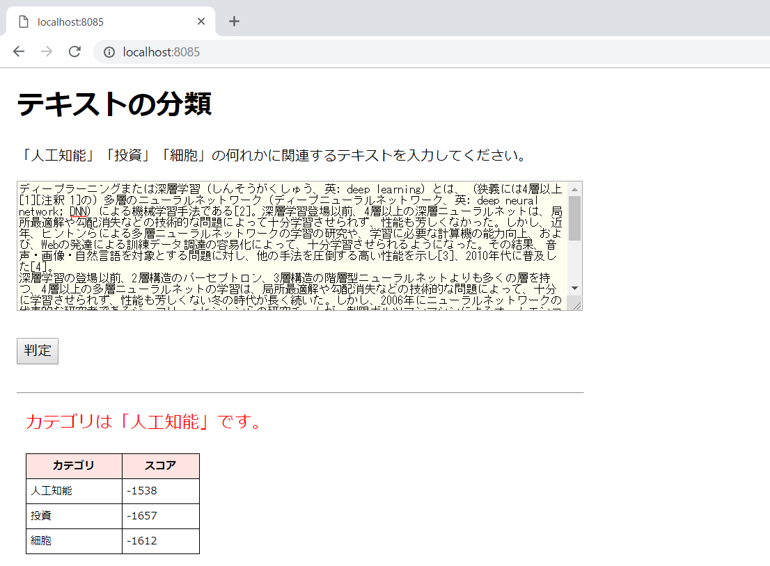
結果は期待通り「人工知能」のカテゴリに分類されました。このとき、判定するにあたり、各カテゴリのスコアが表示されました。このスコアの大きさに応じてカテゴリを判定します。
このスコアは相対的な指標なので、値の絶対値は意味を持ちません。他のカテゴリと比較して、相対的に差が大きいほど精度よく分類されたと解釈できます。今回は、「人工知能」のカテゴリのスコアが相対的に大きいことが確認できます。対数表示なので値はマイナスです。
3.2.「iPS細胞」を判定
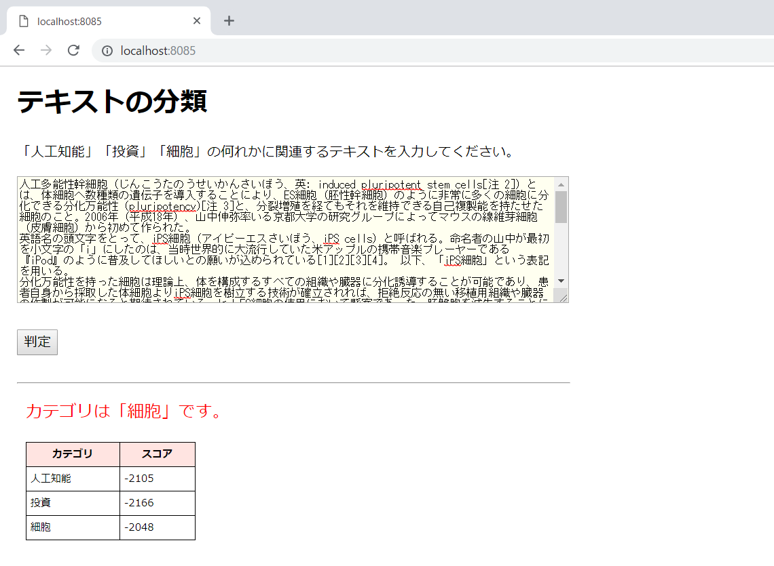
次は、Wikipediaで「iPS細胞」を検索した文書を入力してみます。結果は期待通り「細胞」のカテゴリに分類されました。
3.3.「NISA」を判定
最後は、Wikipediaで「NISA」を検索した文書を入力してみます。結果は期待通り「投資」のカテゴリに分類されました。
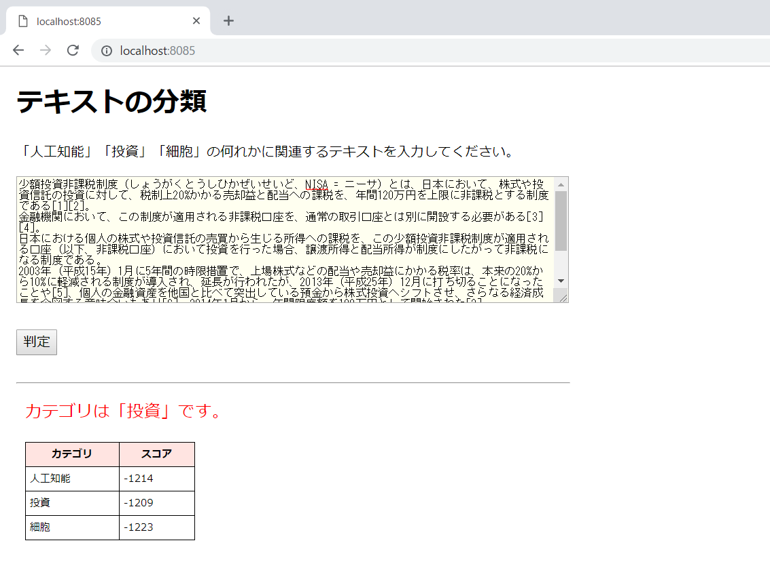
ただし、スコアを確認してみると、3つのカテゴリにそこまで差がありませんでした。今回は何とか「投資」のカテゴリに分類されましたが、入力する文書によっては期待するカテゴリに分類されない可能性もあります。
原因としては、今回の機械学習で使用した「投資」カテゴリのデータが不足していたと考えられます。もっと多くの文書を学習させることで、分類の精度を向上させることができると思われます。
4. 利用シーン
テキストや文書の分類は下記の事例などに利用できると思います。応用例としては、分類したカテゴリに応じて、次のアクションを起動させるなどの処理が考えられるでしょう。
- メールのカテゴリ分類
- 迷惑メールの判定
- 記事の分類やタグ付け
- お問い合わせ内容に応じた回答(応用例)
- Webの記事内容に応じた投資判断(応用例)
5. 参考図書
今回のアプリを作る上で参考にした書籍を紹介しておきます。
「増補改訂Pythonによるスクレイピング&機械学習 開発テクニック」
まとめ
今回はPythonの機械学習を使って、テキスト・文書を自動で分類してみました。要点を下記にまとめておきます。
- 機械学習でテキストや文書をカテゴリ別に分類できる
- 特定の単語ではなく、大量のテキストや文書を学習させる
- 学習させるデータが不足すると分類の精度が下がる
- 分類アルゴリズムには「ベイジアンフィルタ(ナイーブベイズ)」を用いた
関連記事
 2022年2月5日 【時系列マップ解説】過去に実践してきたプログラミング言語の具体的な勉強方法と順番
2022年2月5日 【時系列マップ解説】過去に実践してきたプログラミング言語の具体的な勉強方法と順番 2018年8月8日 Pythonの機械学習で言語判定するWebアプリを作ってみた
2018年8月8日 Pythonの機械学習で言語判定するWebアプリを作ってみた 2019年3月3日 【アプリ開発】資産運用を自動化するFinTech開発
2019年3月3日 【アプリ開発】資産運用を自動化するFinTech開発 2024年5月15日 【事例No.10】Vue.jsで「ジョブギルド」の検索機能を開発
2024年5月15日 【事例No.10】Vue.jsで「ジョブギルド」の検索機能を開発